GPT-5.5 发布后,仔细看数据有三个让人警惕的反差。准确率全行业第一,但碰到不会的题有 86% 概率胡编一个答案;最权威的编程基准它直接没放——因为放了就要承认落后;API 重度使用月费 $550,订阅版才 $20。
01 越聪明越敢瞎编
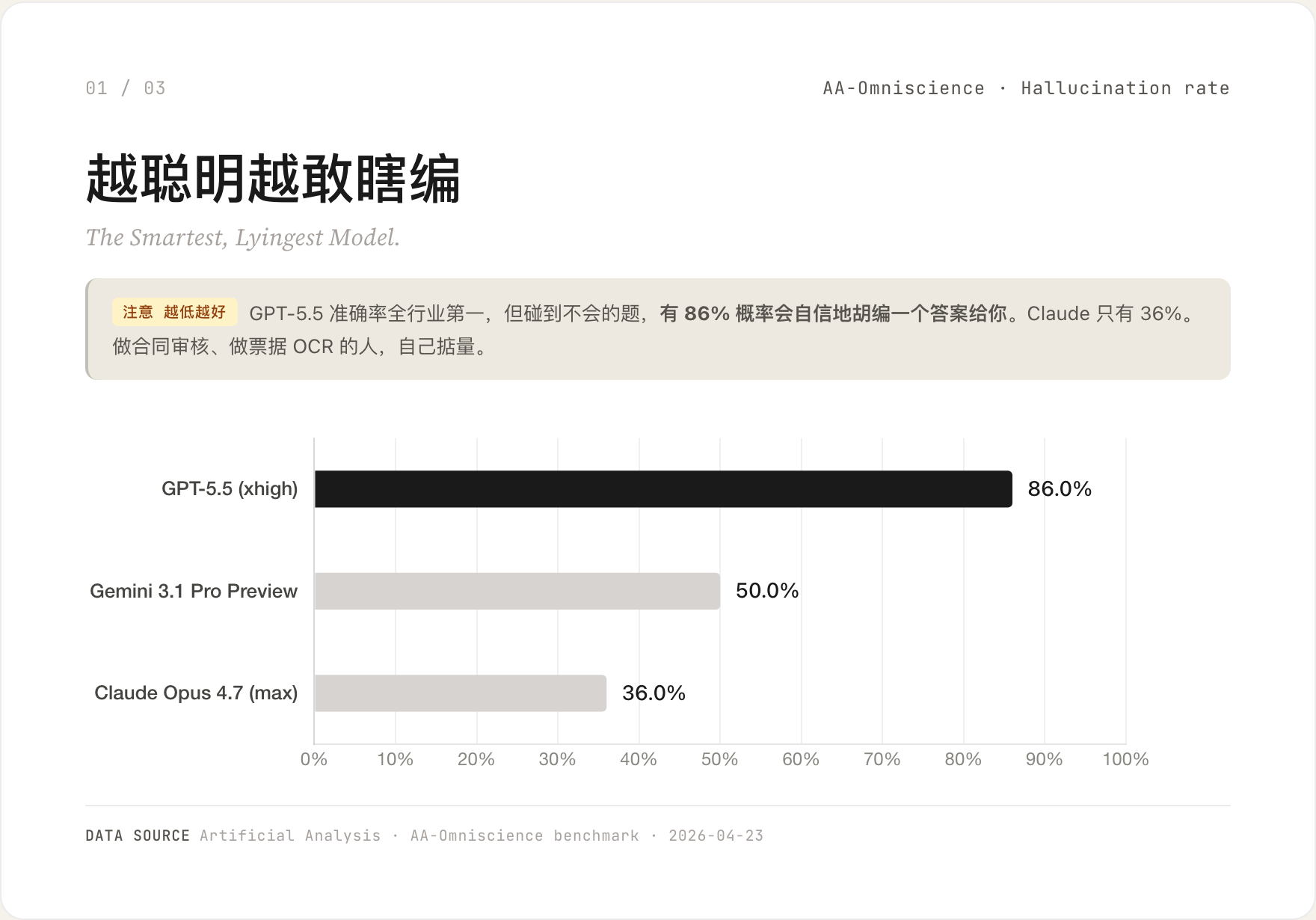
GPT-5.5 在 AA-Omniscience 这项基准上,准确率排到了全行业第一。但同一个基准还测了另一个数字:当模型碰到不会的题时,它会承认不会,还是自信地胡编一个答案?
GPT-5.5 的幻觉率是 86%。Gemini 3.1 Pro 是 50%。Claude Opus 4.7 只有 36%。
差距大到这个程度,方向也很清楚——OpenAI 优化的是「看起来回答对了」,Anthropic 优化的是「知道自己什么时候不该回答」。
做合同审核、票据 OCR、医疗资料整理这一类不能容错的工作,自己掂量这个数字。
02 消失的 benchmark
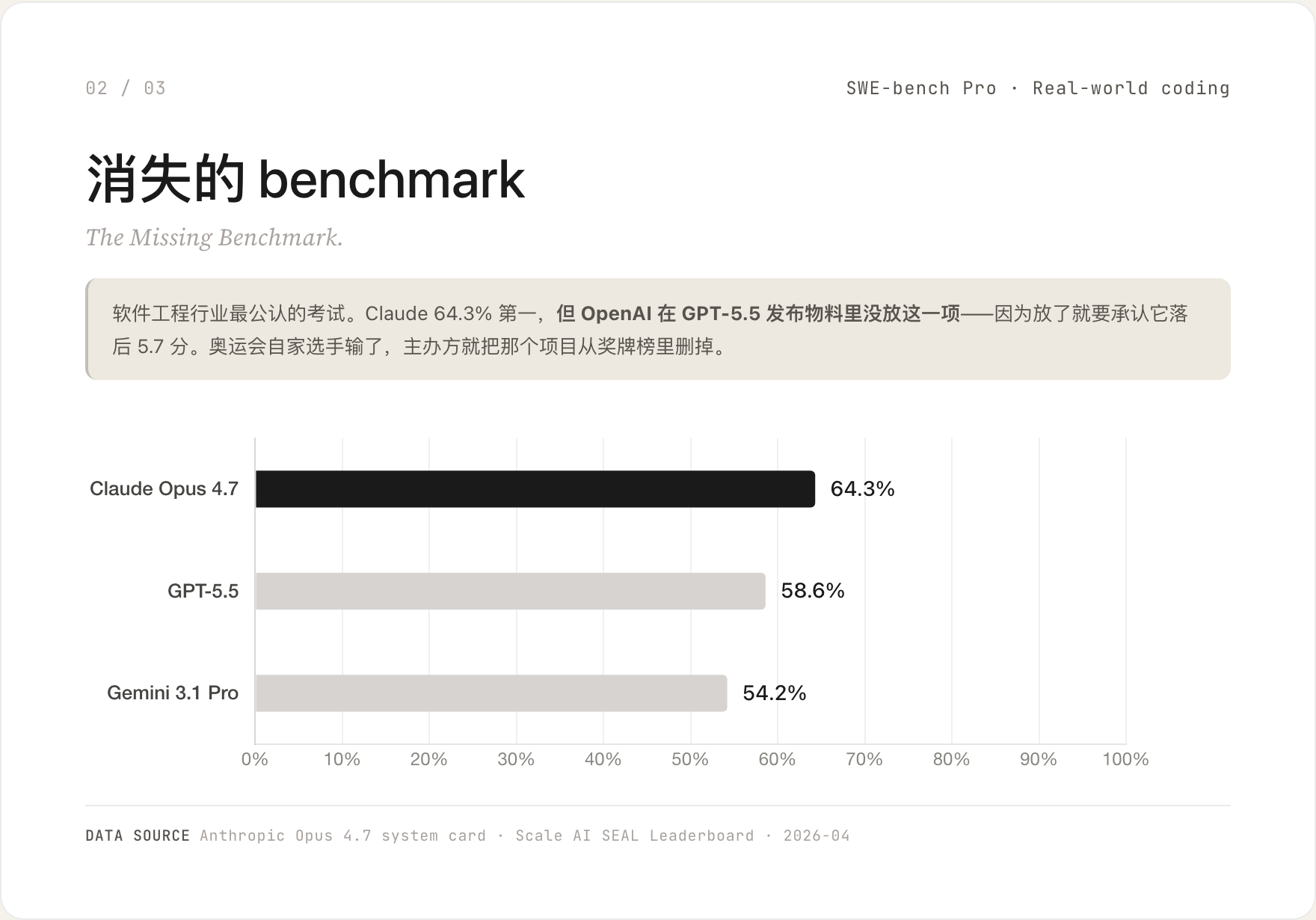
SWE-bench Pro 是软件工程行业目前最公认的基准——给模型一个真实代码库,让它修一个真实的 bug。
Claude Opus 4.7 跑出 64.3%,行业第一。GPT-5.5 是 58.6%,落后 5.7 分。
但 OpenAI 在 GPT-5.5 的发布物料里完全没放这一项。要在它的 system card 里翻才看得到。
奥运会自家选手输了,主办方就把那个项目从奖牌榜里删掉。这不是技术问题,是营销选择。
03 用 API 是冤大头
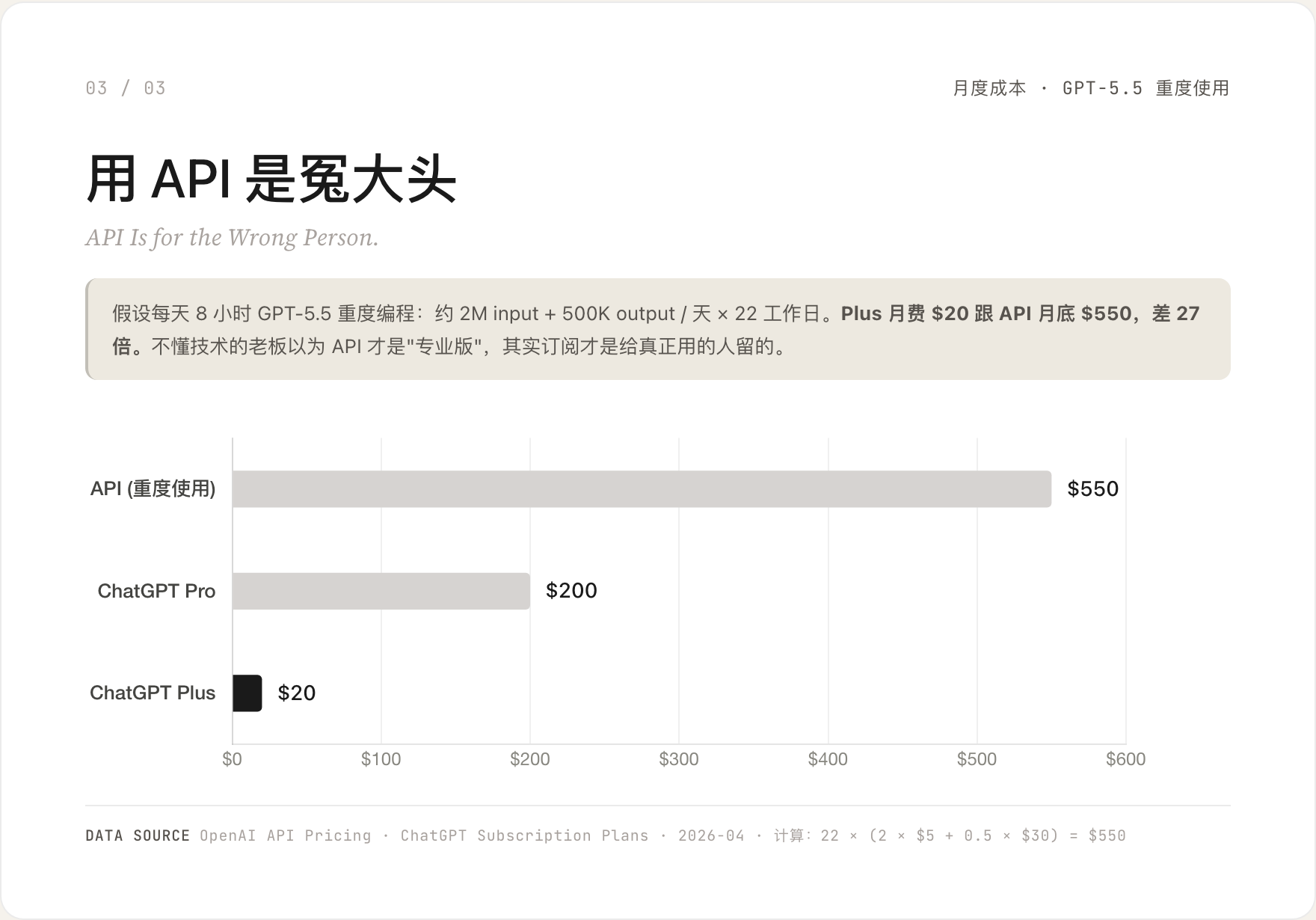
假设一个开发者每天 8 小时拿 GPT-5.5 重度编程:约 200 万 input + 50 万 output,按 22 个工作日算。
API 月底账单:$550。ChatGPT Plus 月费:$20。差 27.5 倍。
不懂技术的老板以为 API 才是「专业版」,掏钱掏得心安理得。其实订阅才是给真正高频用的人留的。
API 真正适合的是按量、间歇、批处理的场景——比如你在做一个每天给 100 个用户用一次的小工具。每天 8 小时一直在调用的人,订阅一定更划算。
三个反差点指向同一件事:发布会上那些数字,是 OpenAI 选给你看的。决定要不要换 GPT-5.5 之前,去翻一下它没主动放的那几项基准,再算一下你真实的使用频次——结论可能完全不一样。