GPT-5.5 在 8 个核心基准上和 Claude、Gemini 的对比。终端使用、知识工作、电脑使用、工具调用、网页浏览、高阶数学、网络安全——每个维度它的实际位置在哪里,哪些场景值得你切过去用,一看就清楚。
OpenAI 在 GPT-5.5 的发布里挑了一些数字给你看。下面是它真实跑过的 8 个公开基准,所有数据都从它自己的 system card 和第三方榜单上来。每张图都是一个独立的应用场景,看完心里就有数——你的工作流值不值得切到 GPT-5.5。
01 终端使用 / Terminal-Bench 2.0
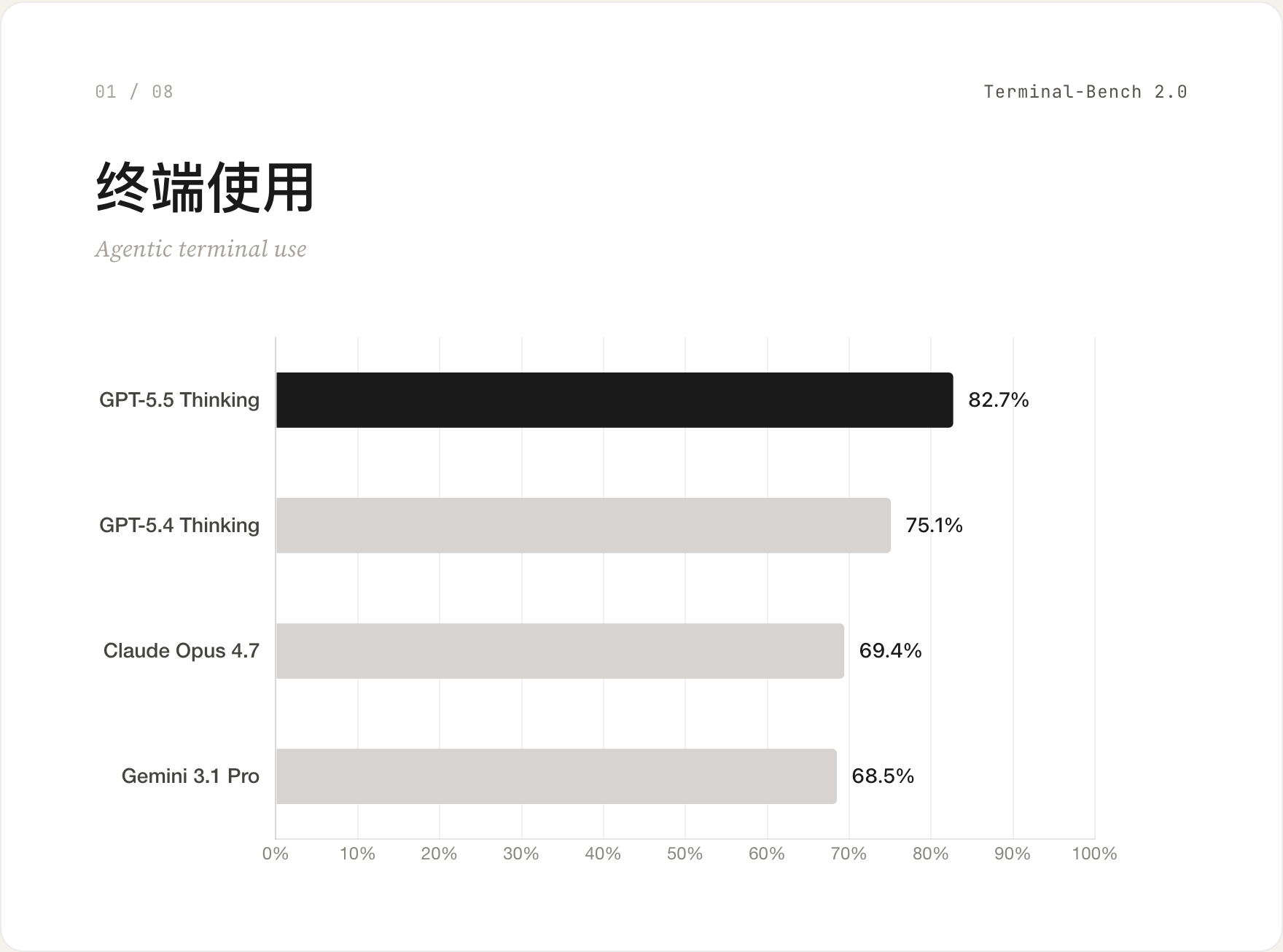
GPT-5.5 Thinking 跑出 82.7%,比 Claude Opus 4.7 的 69.4% 高出 13 分。这是它打得最干净的一个场景——给它一个终端、一个目标,让它自己装环境、运行命令、修问题。
02 知识工作 / GDPval
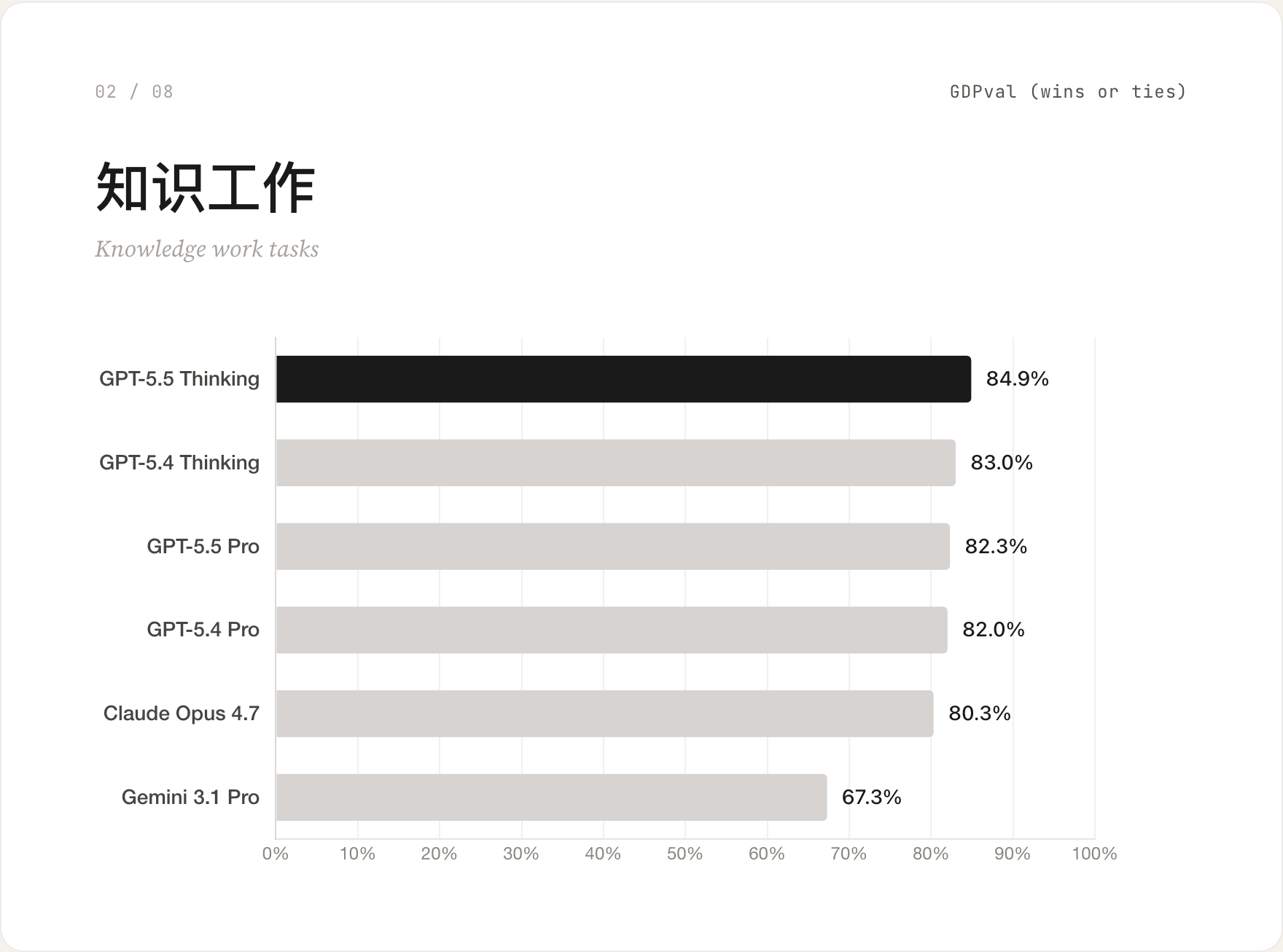
把模型放到真实的白领任务里:写报告、整理数据、做研究综述。GPT-5.5 Thinking 84.9% 第一,但前五名差距在 3 个百分点以内。这个场景里换哪家都差不多。
03 电脑使用 / OSWorld-Verified
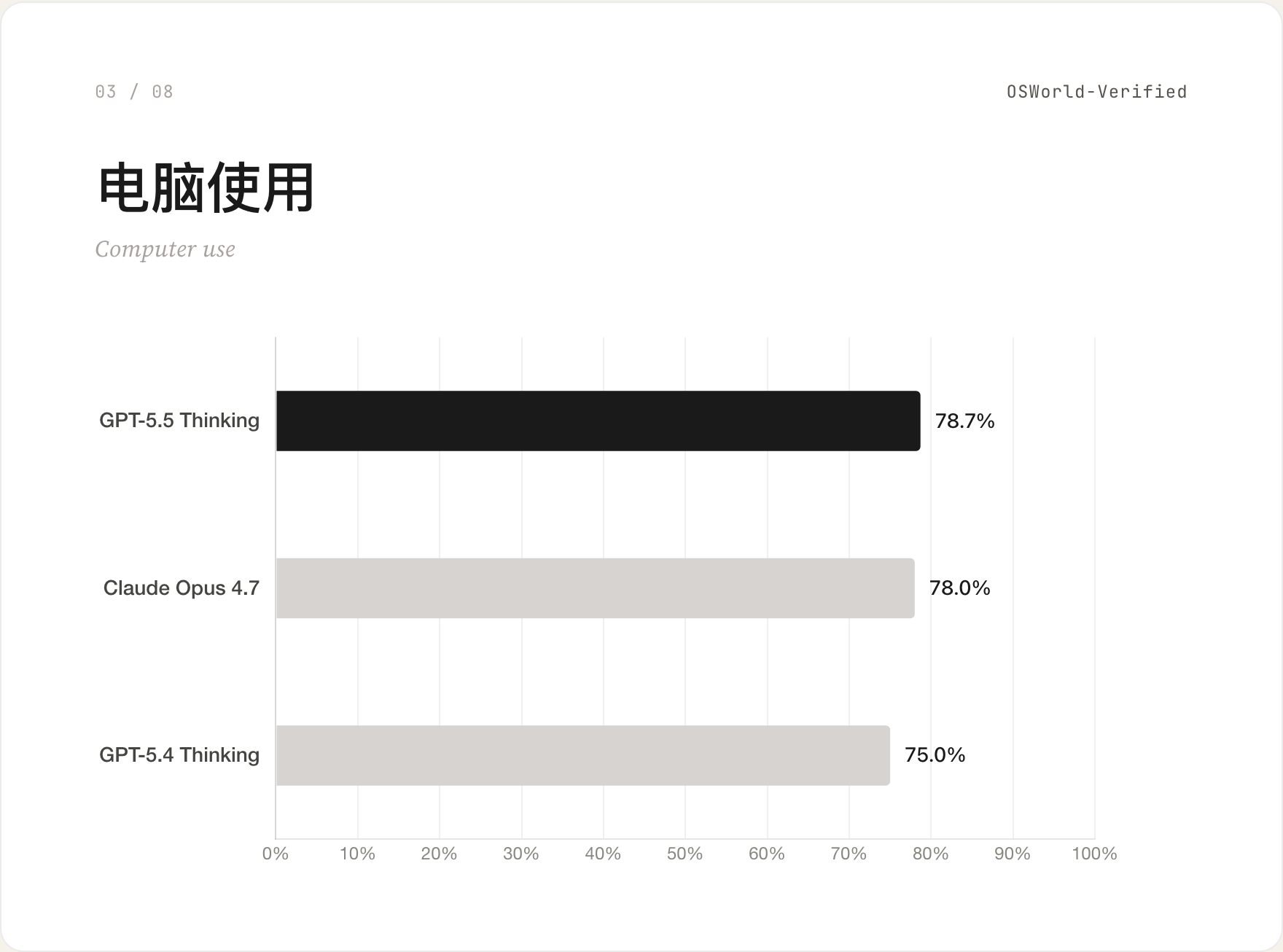
让模型操作整台电脑——点击、键盘、看屏幕。GPT-5.5 Thinking 78.7% 险胜 Claude Opus 4.7 的 78.0%,差距小到几乎可以忽略。
04 工具调用 / Toolathlon
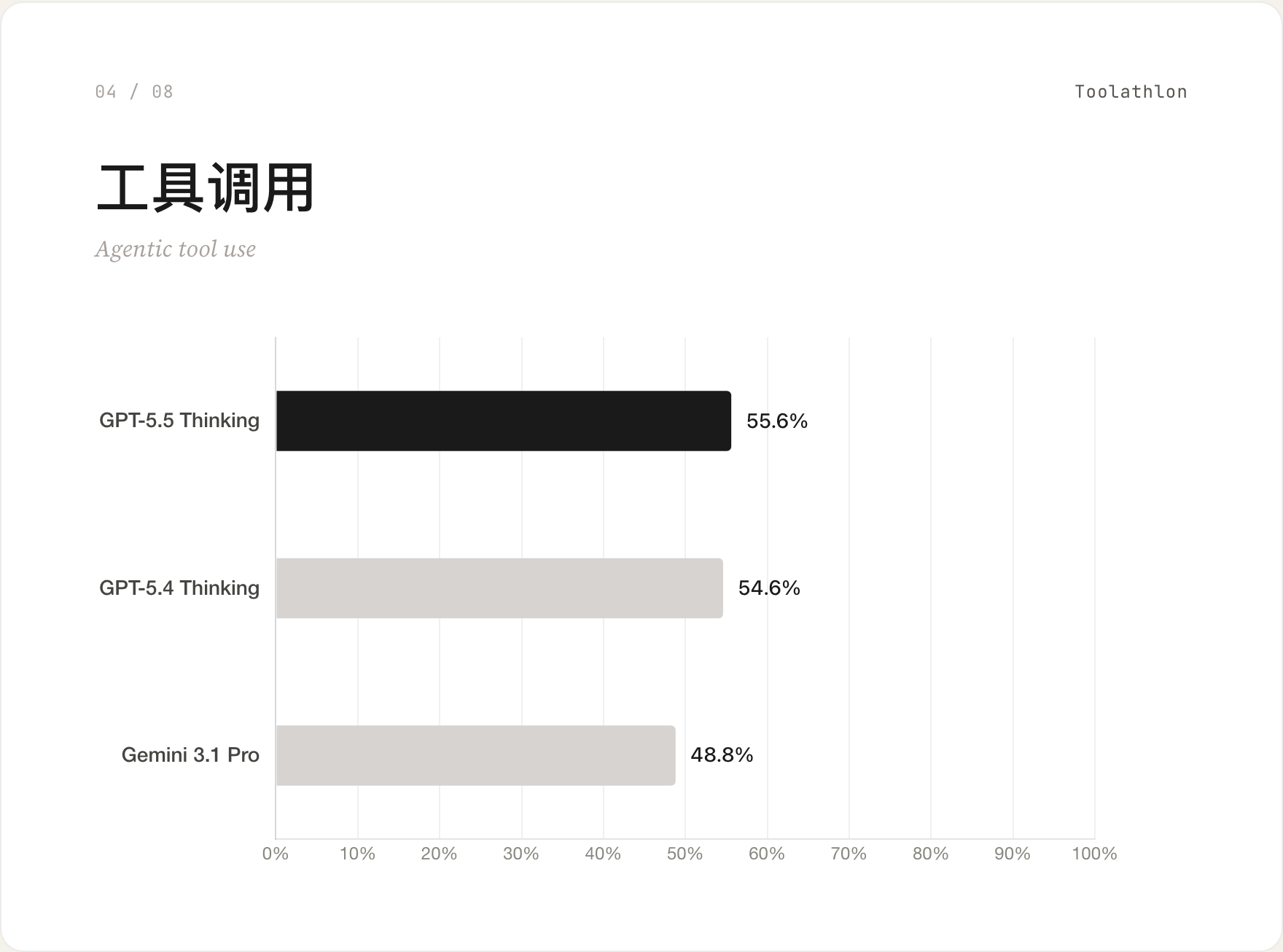
调用外部工具完成任务的能力。GPT-5.5 Thinking 55.6% 排第一,Gemini 3.1 Pro 48.8%。三家都没过 60,说明这件事整个行业都还没解决好。
05 网页浏览 / BrowseComp
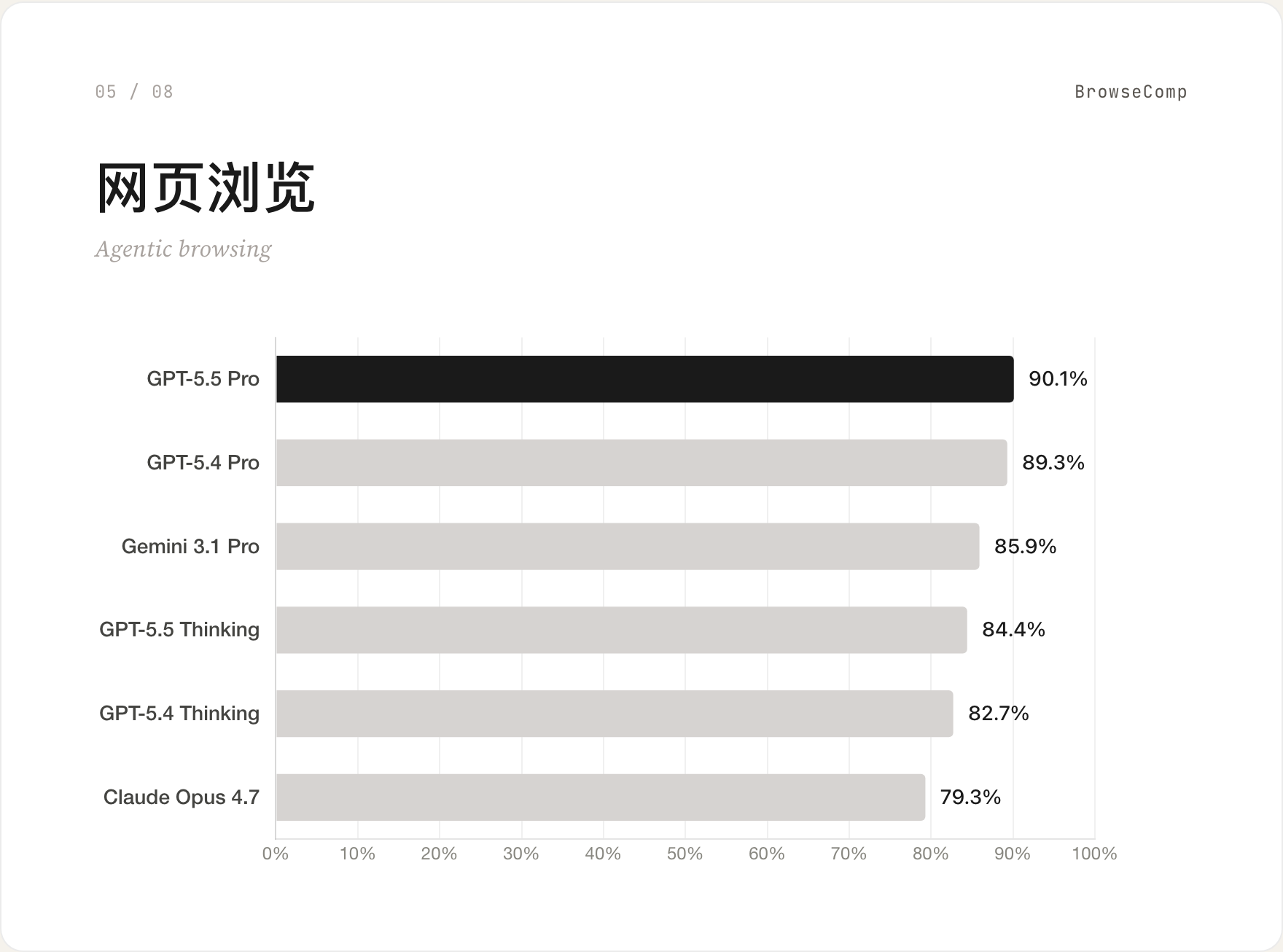
GPT-5.5 Pro 90.1% 第一,但只比 GPT-5.4 Pro 的 89.3% 高 0.8 分。值得注意的是 Gemini 3.1 Pro 在这一项跑到了 85.9%——比 GPT-5.5 Thinking(84.4%)和 Claude Opus 4.7(79.3%)都高。
06 高阶数学 / FrontierMath Tier 1-3
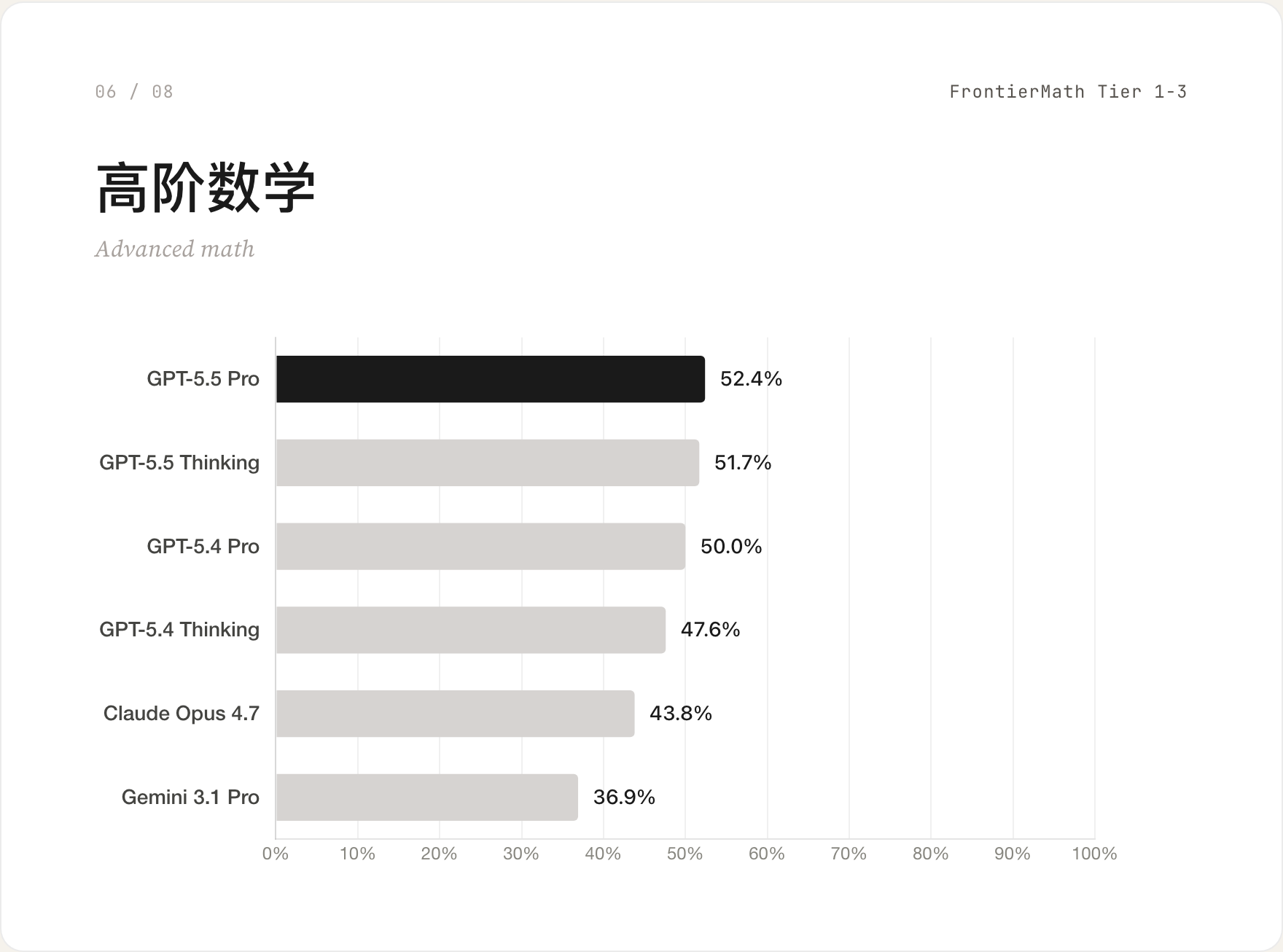
GPT-5.5 Pro 52.4% 险胜 GPT-5.5 Thinking 的 51.7%。但更重要的是:所有模型都在 50% 上下,说明这个层级的题已经接近被攻破。下一个真正的分水岭是 Tier 4。
07 数学家级数学 / FrontierMath Tier 4
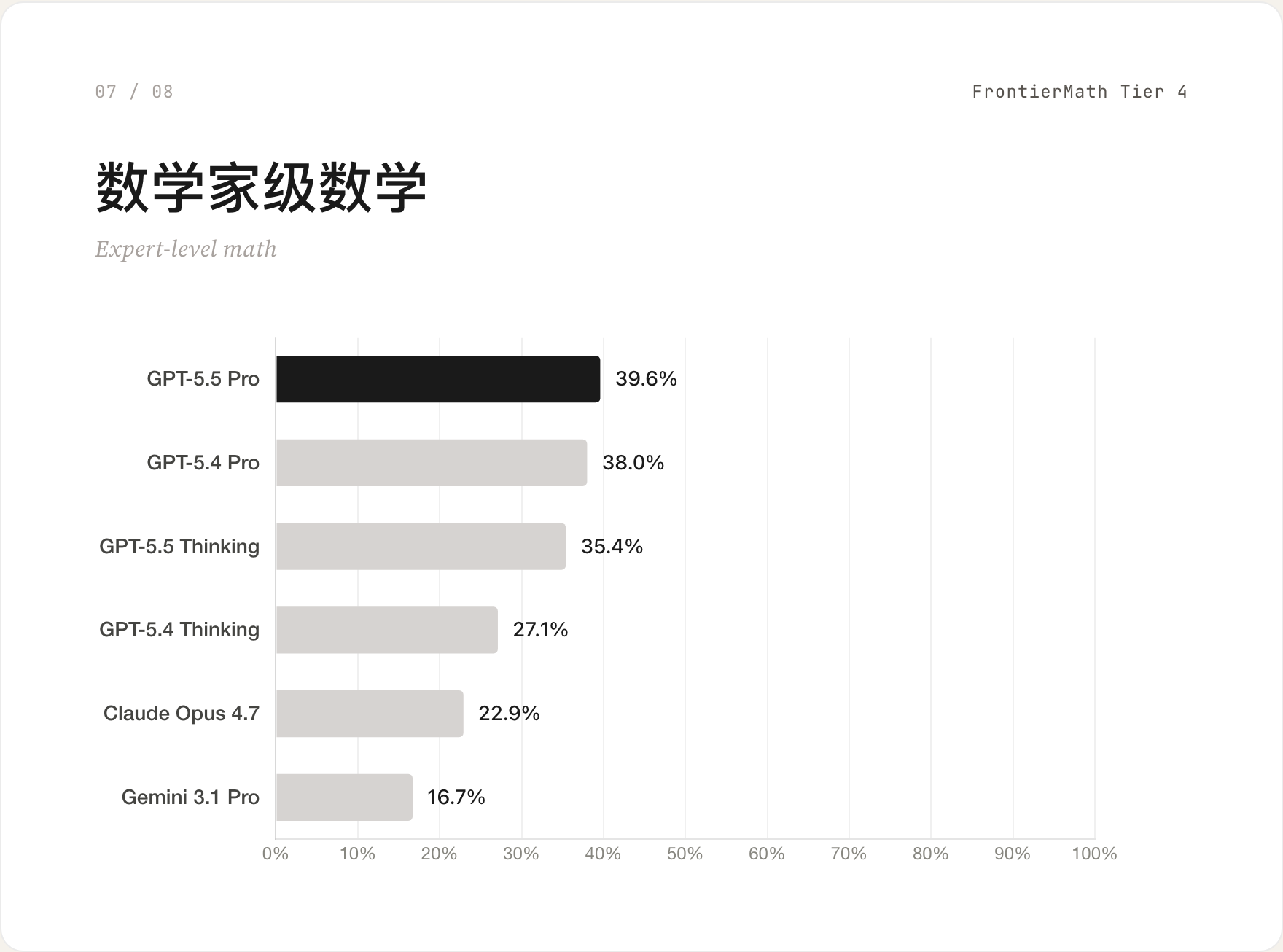
Tier 4 是真正接近职业数学家工作的题。GPT-5.5 Pro 39.6% 第一,Claude Opus 4.7 22.9%,Gemini 3.1 Pro 16.7%。这是 GPT-5.5 拉开最大差距的场景——领先 Claude 接近 17 分。
08 网络安全 / CyberGym
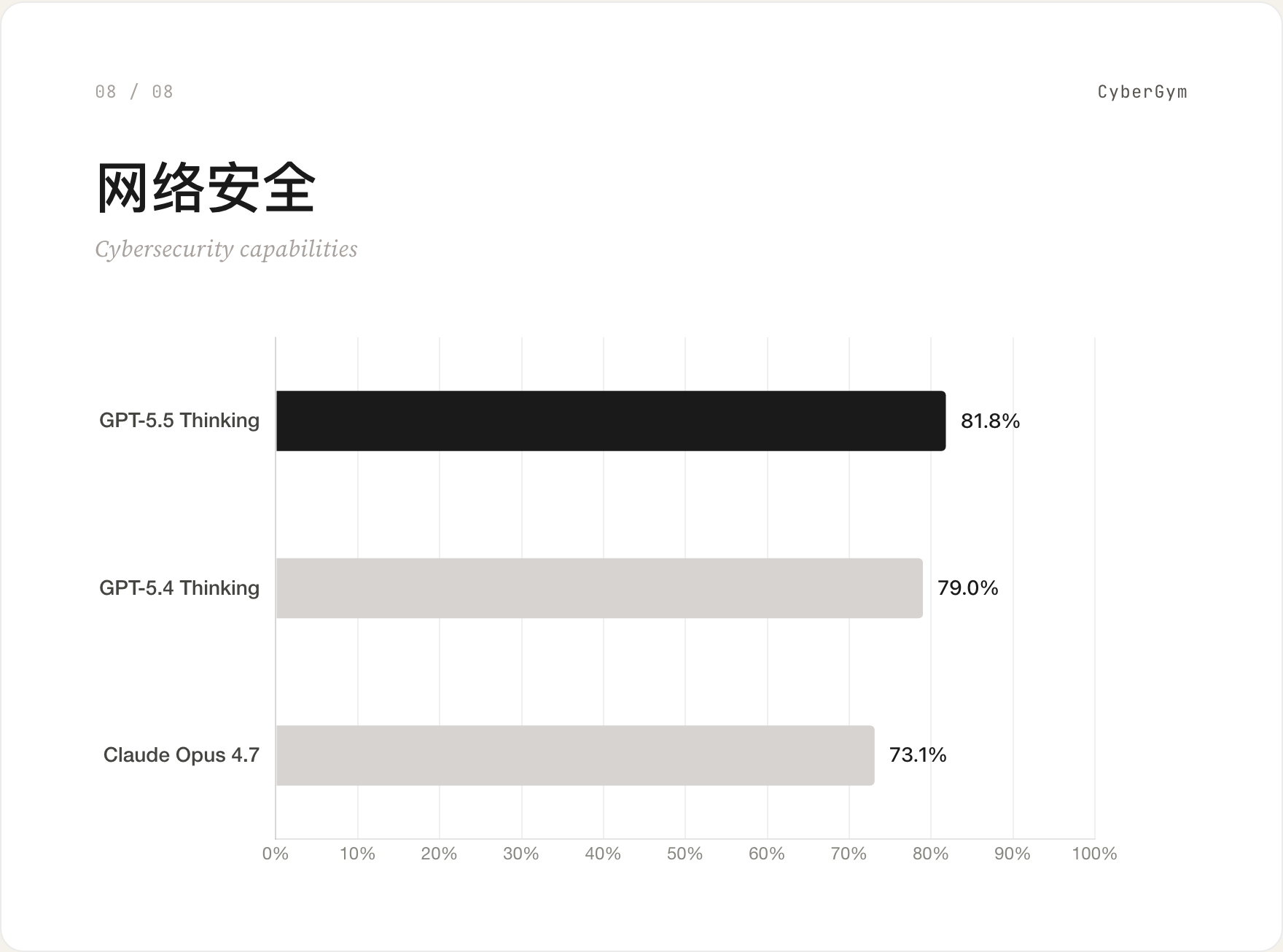
GPT-5.5 Thinking 81.8%,比 Claude Opus 4.7 的 73.1% 高 8.7 分。安全研究员、red team、漏洞分析这一类的场景,GPT-5.5 是目前最稳的选择。
把 8 张图合起来看:GPT-5.5 在终端、工具调用、高阶数学、网络安全这四个场景拉开了明显距离,其他场景和 Claude、Gemini 三足鼎立。如果你的工作刚好落在前四个里,值得切过去;如果只是日常知识工作,现在这个时点没必要为单价多一倍买单。